As artificial intelligence continues to advance, businesses and individuals increasingly seek to harness the power of language models. Building a private language model, or LLM, can enhance privacy, security, and customization to suit specific needs. This guide will walk you through the steps required to build your own private LLM.
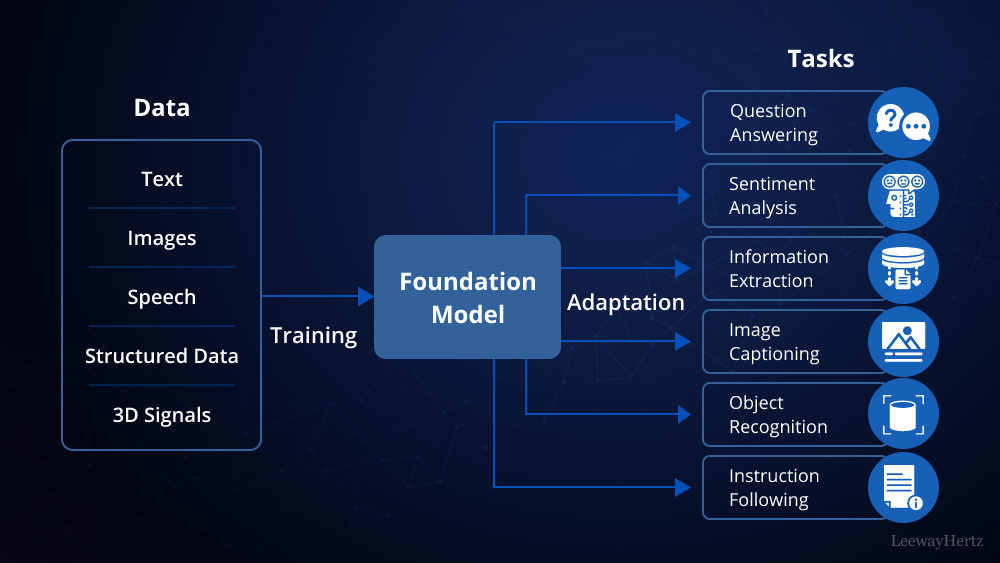
Understanding Language Models
Before diving into the construction of a private LLM, it’s essential to understand what a language model is. An LLM is an AI system trained to understand and generate human language. Models like GPT-4 are examples of large language models capable of tasks such as translation, summarization, and conversation.
Why Build a Private LLM?
- Data Privacy: Sensitive information remains in-house.
- Customization: Tailor the model to specific jargon or use-cases.
- Cost Efficiency: Potentially reduce costs over time with self-hosting.
Step-by-Step Guide to Building a Private LLM
1. Define Your Objectives
Clearly outline why you need a private LLM. Determine the specific tasks it should perform, the type of data it will handle, and any special requirements such as compliance with data privacy regulations.
2. Choose the Right Framework
Selecting the appropriate framework is crucial. Popular frameworks include:
- TensorFlow: Versatile and widely used.
- PyTorch: Known for its dynamic computational graph and ease of use.
3. Gather and Prepare Data
High-quality data is the backbone of any successful LLM. Follow these steps to prepare your dataset:
- Collect Data: Gather text data relevant to your use case.
- Clean Data: Remove duplicates, correct errors, and standardize formats.
- Annotate Data: If needed, annotate your data for specific tasks (e.g., tagging parts of speech).
4. Preprocess the Data
Preprocessing converts raw data into a format suitable for model training. Common steps include:
- Tokenization: Splitting text into words or subwords.
- Normalization: Lowercasing and removing punctuation.
- Vectorization: Converting tokens into numerical vectors.
5. Select a Pre-trained Model
Starting with a pre-trained model can significantly reduce the time and resources required. Models like GPT-4, BERT, or T5 are excellent starting points. These models can be fine-tuned to your specific needs.
6. Fine-tune the Model
Fine-tuning involves adjusting a pre-trained model with your specific dataset. This step requires substantial computational resources. Here’s a simplified process:
- Set Up Environment: Ensure you have a powerful GPU and necessary software (Python, PyTorch, TensorFlow).
- Load Pre-trained Model: Utilize libraries like Hugging Face’s Transformers.
- Train the Model: Adjust parameters, monitor performance, and prevent overfitting.
7. Evaluate the Model
Evaluate the performance of your fine-tuned model using metrics such as:
- Accuracy: Correctness of predictions.
- Precision and Recall: Balance of true positives against false positives and negatives.
- F1 Score: Harmonic mean of precision and recall.
8. Optimize and Deploy
Optimization involves improving the model’s efficiency and effectiveness. Techniques include:
- Pruning: Removing unnecessary parts of the model.
- Quantization: Reducing the precision of the numbers used in the model.
- Distillation: Creating a smaller, faster model that retains the performance of a larger one.
Once optimized, deploy the model on your private server or cloud infrastructure. Ensure the environment supports scalability and security.
9. Maintain and Update
Regular maintenance is vital for the continued performance of your LLM:
- Monitor Performance: Continuously track accuracy and efficiency.
- Update Data: Refresh the training data to keep the model relevant.
- Retrain Periodically: Adapt the model to changing data and requirements.
Tools and Resources
- Hugging Face Transformers: Provides a variety of pre-trained models and tools for fine-tuning.
- Google Colab: Offers free GPU resources for initial experiments.
- Docker: Facilitates the deployment of your model in a consistent environment.
Conclusion
Building a private LLM involves careful planning, selecting the right tools, and ongoing maintenance. By following the steps outlined above, you can create a robust, customized language model that meets your specific needs while ensuring data privacy and security. Embrace the power of AI and transform how you handle language-related tasks by building your own private LLM.

Leave a comment